


A recent survey by Kaggle revealed that data professionals used a variety of different algorithms, tools, frameworks and products to extract insights. Top algorithms were linear/logistic regression, decision trees/random forests and Gradient Boosting Machines. Top frameworks were Scikit-learn and TensorFlow. Top tools for automation were related to model selection and data augmentation. While half of the respondents did not use ML products, the top products used were Google Cloud ML Engine, Azure ML Studio and Amazon Sagemaker.
Machine learning is employed by data scientists to find patterns and predict important outcomes. The application of machine learning reaches across industries (e.g., healthcare, education) and professions (e.g., marketing, content management), and data professionals have many different tools, methods and products they can use to extract useful insights. Kaggle conducted a survey in October 2019 of nearly 20,000 data professionals (2019 Kaggle Machine Learning and Data Science Survey) that reveals the variety of ways they solve their machine learning problems. Today’s post is about the machine learning methods and tools data professionals used in 2019.
Most Used Machine Learning Algorithms
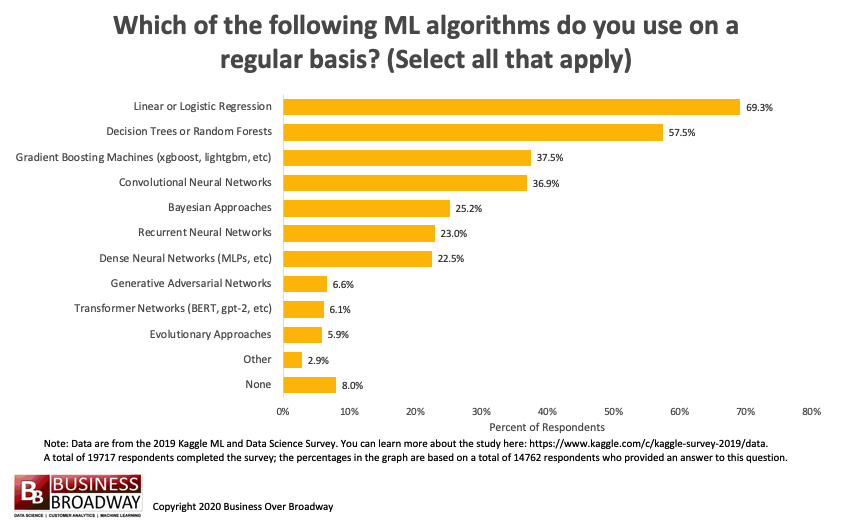
Figure 1. Top Machine Learning Algorithms Used in 2019. Click image to enlarge.
The survey included a question for data professionals, “Which of the following machine learning algorithms do you use on a regular basis? Select all that apply.” On average, data professionals used 3 (median) machine learning algorithms. The top 10 machine learning algorithms used were (see Figure 1):
- Linear or Logistic Regression (69%)
- Decision Trees or Random Forests (58%)
- Gradient Boosting Machines (xgboost, lightgbm, etc) (38%)
- Convolutional Neural Networks (37%)
- Bayesian Approaches (25%)
- Recurrent Neural Networks (23%)
- Dense Neural Networks (23%)
- Generative Adversarial Networks (7%)
- Transformer Networks (6%)
- Evolutionary Approaches (6%)
Adoption rates for the top two algorithms were the highest for data professionals who self-identified as “statistician” and “data scientist.” Adoption rates were around 10 percentage points higher for these data pros (e.g., ~80% for linear/logistic regression, ~70% for decision trees and random forests).
A recent poll by KDNuggets found similar results to the current study. In their study, machine learning methods also included regression (56%), decision trees/rules (48%), random forests (45%), Gradient Boosting Machines (23%).
Most Used Machine Learning Frameworks
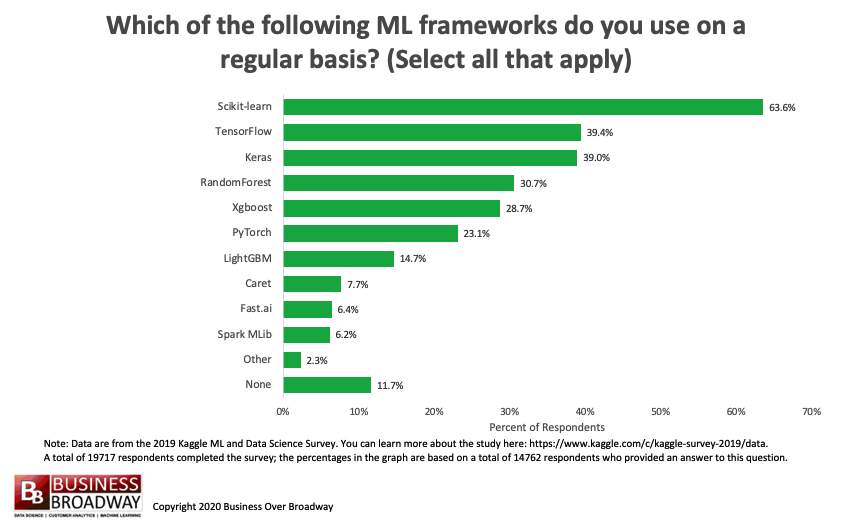
Figure 2. Machine Learning Frameworks Used. Click image to enlarge.
The survey included a question, “Which of the following machine learning frameworks do you use on a regular basis? Select all that apply.” On average, data professionals used 2 (median) machine learning frameworks. The top 10 machine learning frameworks used were (see Figure 2):
- Scikit-learn (64%)
- TensorFlow (39%)
- Keras (39%)
- RandomForest (31%)
- Xgboost (29%)
- PyTorch (23%)
- LightGBM (15%)
- Caret (8%)
- Fast.ai (6%)
- Spark MLib (6%)
Most Used Machine Learning Tools (Automation)
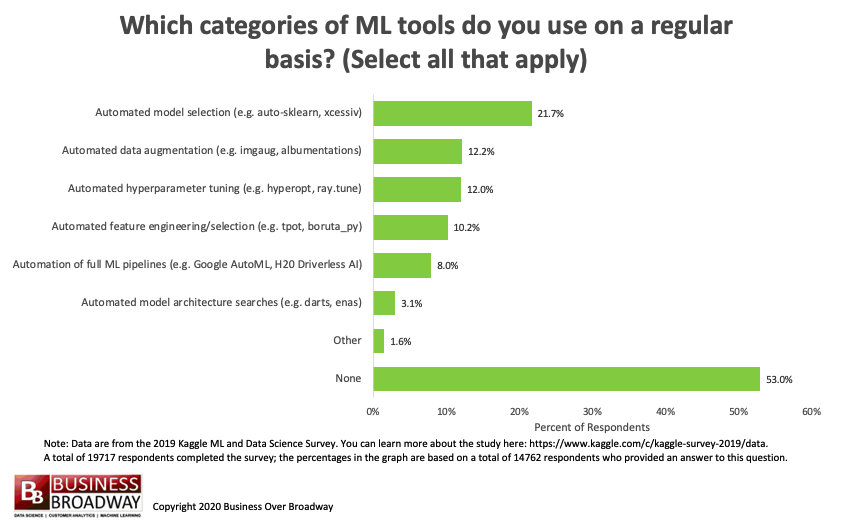
Figure 3. Machine Learning Tools Used. Click image to enlarge.
The survey also asked all data professionals about the machine learning tools they used. A little over half of the respondents (53%) indicated that they did not use any automated machine learning tools. The most used automated machine learning tool used were (see Figure 3):
- Automated model selection (22%)
- Automated data augmentation (12%)
- Automated hyperparameter tuning (12%)
- Automated feature engineering/selection (10%)
- Automation of full ML pipelines (8%)
Most Used Machine Learning Products
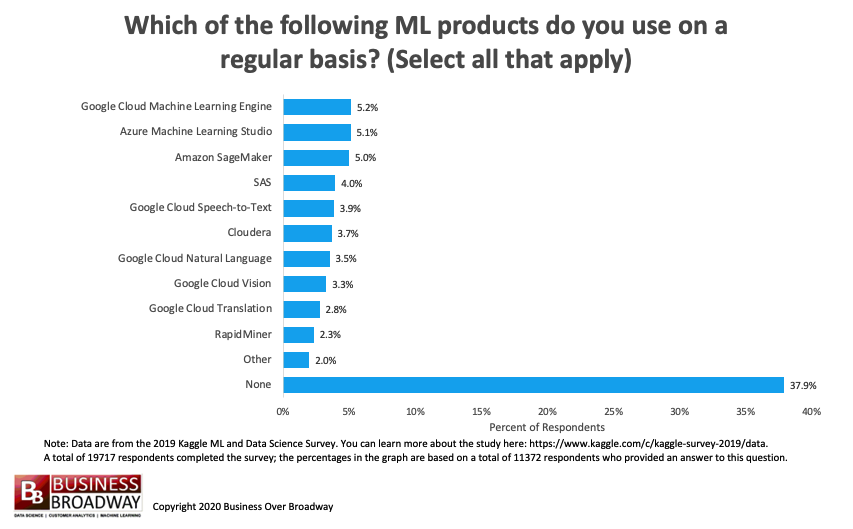
Figure 4. Machine Learning Products Used. Click image to enlarge.
The survey also asked all data professionals about the machine learning products they used. A little over a third of the respondents (38%) indicated that they did not use any machine learning products. The most used automated machine learning products used were (see Figure 4):
- Google Cloud Machine Learning Engine (5.2%)
- Azure Machine Learning Studio (5.1%)
- Amazon SageMaker (5%)
- SAS (4%)
- Google Cloud Speech-to-Text (3.9%)
- Cloudera
- Google Cloud Natural Language
- Google Cloud Vision
- Google Cloud Translation
- RapidMiner
Groupings of ML Algorithms, Frameworks, Tools and Products
I conducted a principal components analysis of all the various machine learning utilities to identify groupings of these machine learning methods. I found a fairly clear 9-component solution:
- Automation tools
- Google products
- TensorFlow / Keras /Dense Neural Networks (MLPs, etc) / Convolutional Neural Networks /Recurrent Neural Networks
- SAS / Cloudera / Caret / RapidMiner
- Spark MLib / Amazon Sagemaker
- Linear/Logistic Regression / Decision Trees or Random Forests / Bayesian Approaches
- RandomForest / Xgboost / LightGBM / Gradient Boosting Machines
- Fast.ai / PyTorch / Transformer Networks (BERT, gpt-2, etc)
- Evolutionary Approaches / Generative Adversarial Networks
Azure Machine Learning Studio stood out as the lone product as it did not load on any of the 9 components.
The pattern of results show that the various machine learning methods tend to be used together. For example, when ML automation tools are used, data professionals tend to use all of them. Similarly, data professionals either tend use all Google products or use none of them. Data professionals who employ evolutionary approaches also tend to use generative adversarial networks.
Summary
The results of the Kaggle survey of nearly 20,000 data professionals reveals the most popular machine learning algorithms, products, tools and frameworks.
While machine learning is still a hot and growing field of data science, over a third of the respondents do not use any ML products. Top algorithms used were linear/logistic regression, decision trees/random forests and Gradient Boosting Machines. The most used machine learning frameworks were Scikit-learn and TensorFlow. Top tools for machine learning automation were related to model selection and data augmentation. The top products used were Google Cloud ML Engine, Azure ML Studio and Amazon Sagemaker.

 Beyond the Ultimate Question
Beyond the Ultimate Question Measuring Customer Satisfaction and Loyalty (3rd Ed.)
Measuring Customer Satisfaction and Loyalty (3rd Ed.)
Comments are closed.