


The practice of data science requires the use algorithms and data science methods to help data professionals extract insights and value from data. A recent survey by Kaggle revealed that data professionals used data visualization, logistic regression, cross-validation and decision trees more than other data science methods in 2017. Looking ahead to 2018, data professionals are most interested in learning deep learning (41%).
Kaggle conducted a survey in August 2017 of over 16,000 data professionals (2017 State of Data Science and Machine Learning). Their survey included a variety of questions about data science, machine learning, education and more. Kaggle released the raw survey data and many of their members have analyzed the data (see link above). I will be exploring their survey data over the next couple of months. When I find something interesting, I’ll be sure to post it here on my blog. Today’s post is about the data science and machine learning methods data professionals used in 2017 and the machine learning / data science method that most excites them in 2018.
Most Popular Data Science/Analytics Tools, Technologies and Languages in 2017
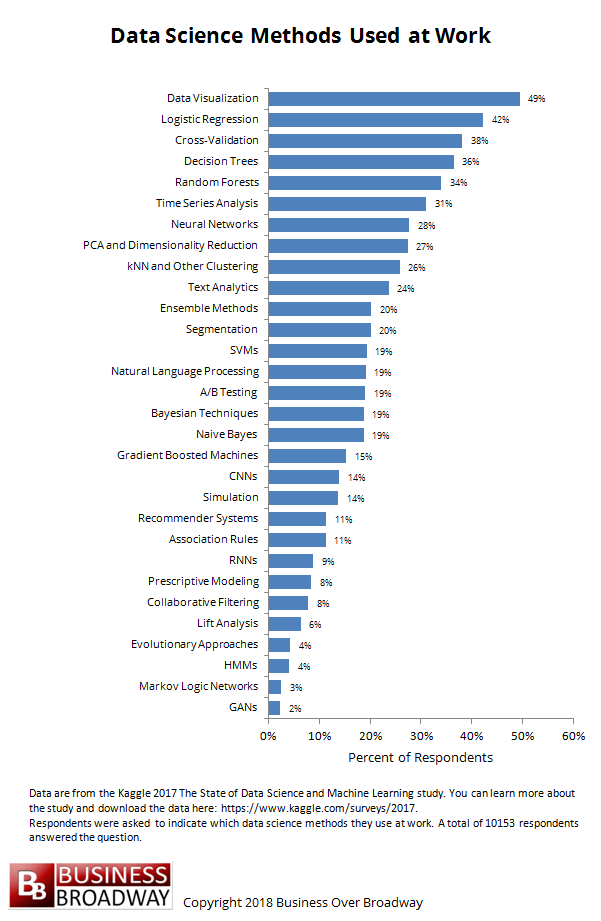
Figure 1. Data Science Methods Used at Work in 2017. Click image to enlarge.
The survey included a question for data professionals who were employed, “At work, how often do you use the following data science methods? (Select all that apply).” On average, data professionals used 5 (median) data science methods in 2017. The top 5 data science methods used in 2017 were (see Figure 1):
- Data Visualization (49%)
- Logistic Regression (42%)
- Cross-Validation (38%)
- Decision Trees (36%)
- Random Forests (34%)
- Time Series (31%)
- Neural Networks (28%)
- PCA and Dimensionality Reduction (27%)
- kNN and other Clustering (26%)
- Text Analytics (25%)
Adoption rates for these methods were higher using only data professionals who self-identified as “data scientists.” Adoption rates were around 15-20 percentage points higher for these data scientists (e.g., 66% for data visualization, 61% for logistic regression, 56% for decision trees and 56% for random forests).
A recent poll by KDNuggets found similar results to the current study. In their study, top data science and machine learning methods also included regression (60%), clustering (55%), visualization (51%), decision trees/rules (51%) and random forests (46%).
[bctt tweet=”In 2017, data professionals used #dataviz, #logisticregression, #crossvalidation and #decisiontrees more than other #datascience methods.” username=”bobehayes”]
Which Machine Learning and Data Science Methods are Data Pros Most Excited about Learning in 2018?
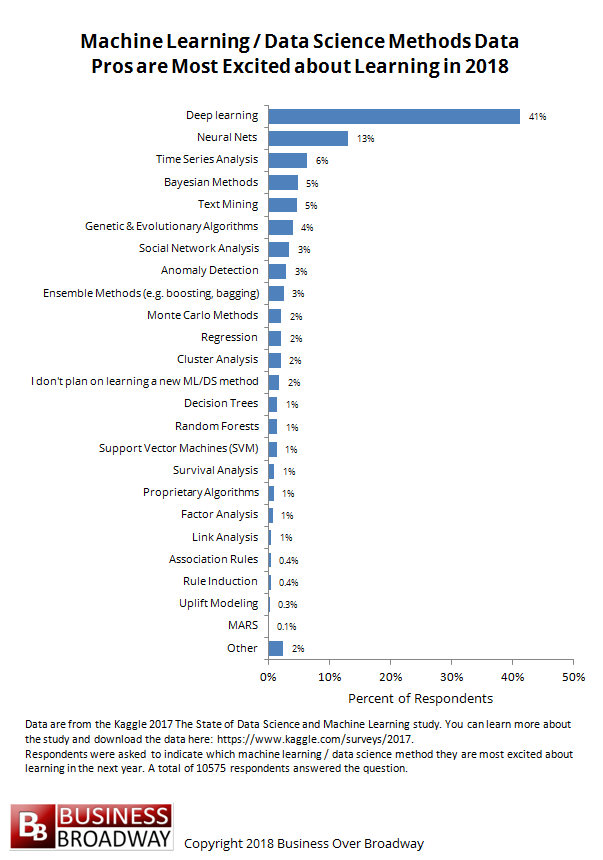
Figure 2. Data Science Tool / Technology Data Pros are Most Excited about Learning in 2018. Click image to enlarge.
The survey also asked all data professionals (working and not) about the machine learning / data science method they are most excited about learning in the next year (see Figure 2). Results showed that data professionals are most interested in learning:
- Deep learning (41%)
- Neural Nets (13%)
- Time Series (6%)
- Bayesian Methods (5%)
- Text Mining (5%)
Summary
The results of the Kaggle survey of over 16,000 data professionals reveals the most popular data science methods that are used at work. Data visualization and logistic regression top the list.
Not surprisingly, 4 out of 10 data professionals said they are most excited to learn about deep learning in the next year. Deep learning is a class of machine learning algorithms that are modeled after the information processing and communication patterns of the brain. Deep learning uses layers of units or nodes for feature extraction and transformation, each layer using the output of the previous layer as input. Deep learning methods can be used in such areas like marketing, automotive, speech recognition and more. In parallel with this interest in learning deep learning, survey results also showed that TensorFlow, a popular open-source software used for deep learning, was the top tool data professionals are interested in learning.

 Beyond the Ultimate Question
Beyond the Ultimate Question Measuring Customer Satisfaction and Loyalty (3rd Ed.)
Measuring Customer Satisfaction and Loyalty (3rd Ed.)
Comments are closed.