


A recent survey by Kaggle revealed that data professionals used a variety of different ML algorithms in their work. On average, data professionals used two (median) algorithms. The most frequently used algorithms were 1) linear/logistic regression, 2) decision trees/random forests and 3) Convolutional Neural Networks. The total number of and use of specific algorithms varied across job titles, with ML engineers using the most (4) and DBA/Database Engineers using the least (1).
Machine learning algorithms are employed by data professionals to predict important outcomes as well as find patterns and structure in their data. The application of machine learning reaches across industries (e.g., healthcare, education) and professions (e.g., marketing, content management). Kaggle conducted a worldwide survey in October 2020 (2020 Kaggle Machine Learning and Data Science Survey), asking over 20,000 data professionals about the work they do, including the ML algorithms they tend to use.
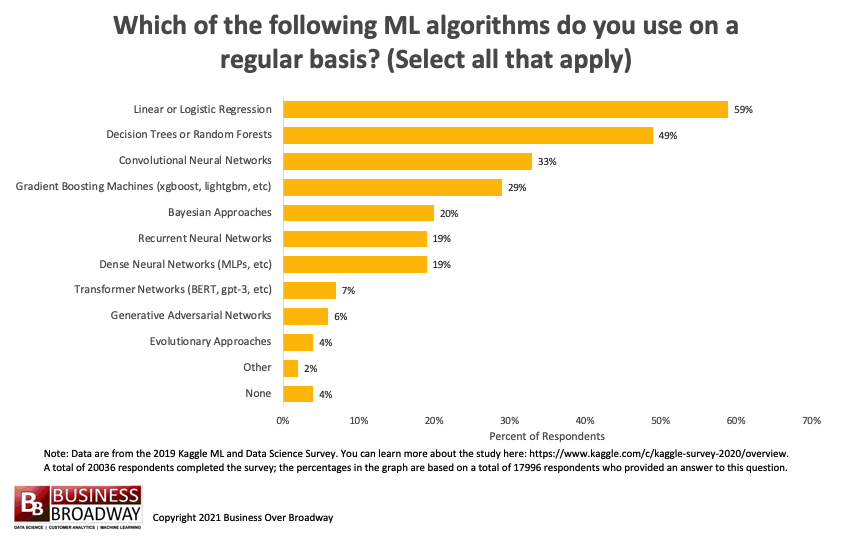
Figure 1. Top Machine Learning Algorithms Used in 2020. Click image to enlarge.
The survey included a question for data professionals, “Which of the following machine learning algorithms do you use on a regular basis? Select all that apply.” On average, data professionals reported that they use 2 (median) machine learning algorithms. The top 10 machine learning algorithms used were (see Figure 1):
- Linear or Logistic Regression (59%)
- Decision Trees or Random Forests (49%)
- Convolutional Neural Networks (33%)
- Gradient Boosting Machines (xgboost, lightgbm, etc) (29%)
- Bayesian Approaches (20%)
- Recurrent Neural Networks (19%)
- Dense Neural Networks (MLPs, etc) (19%)
- Transformer Networks (BERT, gpt-3, etc) (7%)
- Generative Adversarial Networks (6%)
- Evolutionary Approaches (4%)
Data Professionals Use Different Algorithms
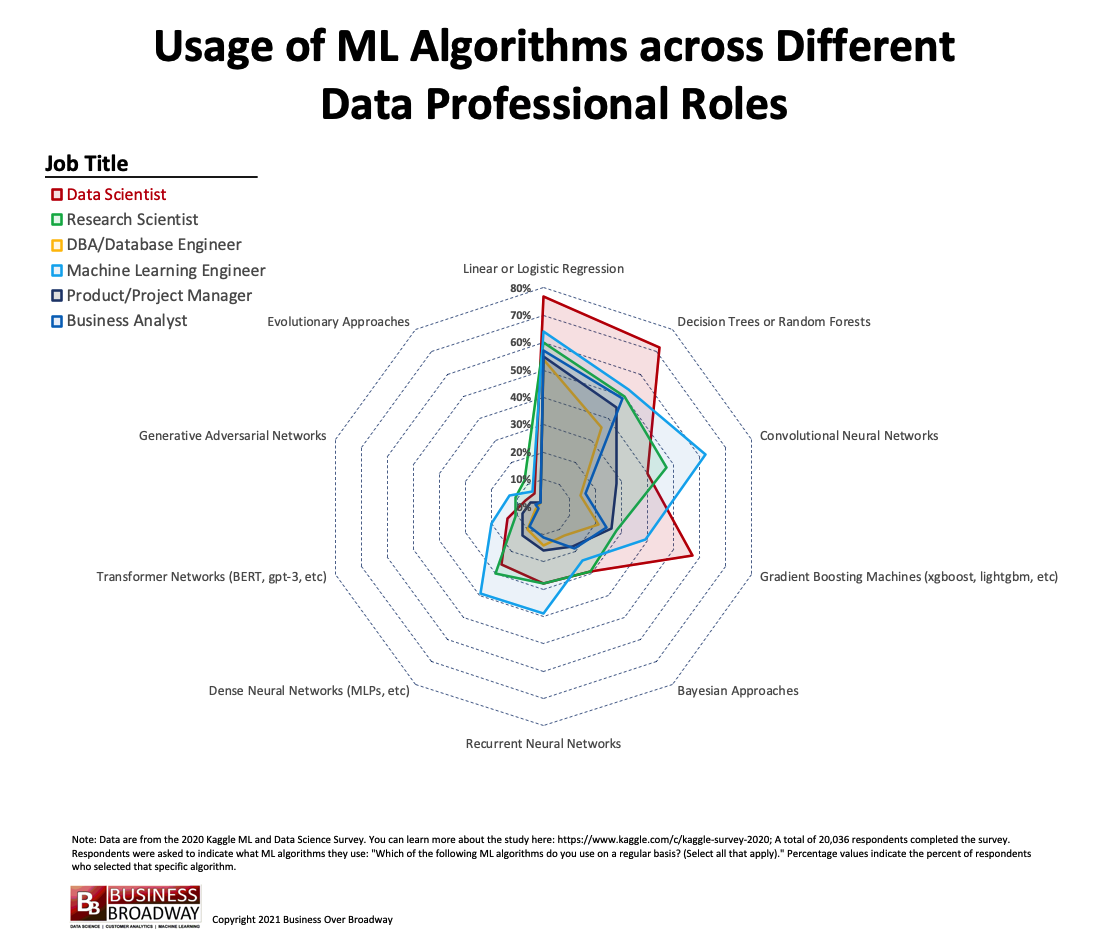
Figure 2. Machine Learning Algorithm Usage Across Different Job Titles for Data Professionals. Click image to enlarge.
Not all data professionals are created equal. Comparing data professionals by job title, we found that the data professionals differed with respect to the number of ML algorithms used and the types of ML algorithms used. Specifically, the survey results revealed that data professionals who used greatest number of algorithms were:
- Machine Learning Engineer (4 algos used)
- Data Engineer (3 used)
- Data Scientist (3 used)
- Research Scientist (3 used)
The job title with the lowest number of algorithms used was DBA/Database Engineer (1 used).
Figure 2 includes information about ML algorithm usage for specific job titles. While Linear or Logistic Regression and Decision Trees or Random Forests were clearly the top algorithms across all data professional, for some data pros, many of them use additional algorithms as part of their work; specifically, many Machine Learning Engineers and Research Scientists use Convolutional Neural Networks (62% and 47%, respectively). More than half of Data Scientists (57%) say they use Gradient Boosting Machines. Finally, more than a third of Machine Learning Engineers (39%) say they use Recurrent Neural Networks and Dense Neural Networks (MLPs, etc) on a regular basis.
It’s not difficult to imagine that the use of ML algorithms is likely related to the type of work activities in which each data professionals are involved. We have seen before that different data roles possess different job activity profiles; work-related activities will necessarily dictate the types of algorithms that are needed to effectively perform each activity. Building and running data infrastructures requires different algorithms than doing research to advance the field of machine learning. Next week, I’ll look at the these activities across the data roles studies in this blog.
When applying for data-related job, it could be useful to understand the typical types of machine learning algorithms you will need to know to be successful in that position. If you’re competent in a variety of ML algorithms, you might be able to successfully broaden your job search to include different data roles.

 Beyond the Ultimate Question
Beyond the Ultimate Question Measuring Customer Satisfaction and Loyalty (3rd Ed.)
Measuring Customer Satisfaction and Loyalty (3rd Ed.)
Comments are closed.