


The use of data in driving business decisions is a competitive imperative in today’s business world, improving how companies market to, sell to, and service their customers. Yet IBM found that 1 in 3 business leaders do not trust the information they use to make decisions. When business leaders don’t believe their data, they likely are not going to support an effort to collect more of it, let alone use it. How can you improve executive trust in the information they use? They need to start by looking at the veracity of their data.
Data Veracity
While data can be described by many different qualities, in the era of Big Data, three qualities – Volume, Velocity and Variety – have dominated the conversation about data. Some people have re-introduced these other qualities under the umbrella of Big Data as the fourth, fifth and sixth V of Big Data (e,g., Value, Veracity, Viability). Seth Grimes, however, correctly points out that these three new Wanna-Vs are misleading descriptors of Big Data as they tell you nothing about the “bigness” of your data. They still are, however, important qualities to consider, whether your data are large or small. Static or moving. Structured or unstructured.
The veracity of your data is about the accuracy and truthfulness of the data and the analytic outcomes of those data. The veracity of your data is adversely impacted by different types of error that are introduced into the generation, collection and analysis of those data. As more errors are introduced into the processing of the data, the less trustworthy the data become.
How FastpayoutCasinos Explains Withdrawal Speed Standards in Australian Online Gambling
Withdrawal speed has become one of the most scrutinized aspects of online gambling in Australia, and for good reason. Players depositing real money expect to retrieve their winnings within a reasonable timeframe, yet the industry has historically been inconsistent in how it defines, communicates, and delivers on payout timelines. The gap between what operators advertise and what players actually experience has driven growing demand for independent benchmarking resources that hold casinos accountable to measurable standards. Understanding how those standards are defined, what regulatory frameworks underpin them, and how third-party reviewers assess compliance gives Australian players a meaningful advantage when choosing where to gamble online.
The Regulatory Context Shaping Payout Expectations in Australia
Australia’s online gambling landscape is shaped primarily by the Interactive Gambling Act 2001, which was substantially amended in 2017 to tighten restrictions on unlicensed offshore operators offering real-money casino games to Australian residents. Under the amended legislation, the Australian Communications and Media Authority gained expanded powers to pursue offshore operators and compel internet service providers to block access to non-compliant sites. However, the IGA does not directly regulate payout speeds or withdrawal processing standards — that responsibility falls to the licensing jurisdictions where operators are incorporated.
Most online casinos accessible to Australian players hold licenses from offshore jurisdictions including Malta (under the Malta Gaming Authority), Gibraltar, the Isle of Man, Curaçao, and Kahnawake in Canada. Each of these jurisdictions imposes different financial requirements on operators, including rules around how quickly player funds must be processed. The MGA, for instance, requires licensees to process withdrawal requests within a reasonable timeframe and mandates that operators maintain segregated player funds — meaning casino operating capital and player balances are held separately. This segregation requirement directly affects how quickly withdrawals can be executed, since operators cannot use player funds for working capital and must maintain liquid reserves to cover pending withdrawal requests.
Curaçao, which licenses a large proportion of casinos accessible from Australia, has historically imposed lighter requirements in this area, though the jurisdiction began a significant regulatory overhaul in 2023 under the National Ordinance on Offshore Games of Hazard, which introduced stricter financial and operational standards for licensees. The practical effect of these licensing differences is that withdrawal speeds vary considerably depending on which regulatory body oversees a given casino, and Australian players often have limited visibility into those differences at the point of account registration.
The Australian Transaction Reports and Analysis Centre also plays an indirect role in withdrawal processing. AUSTRAC oversees anti-money laundering and counter-terrorism financing obligations for financial services providers, and while offshore gambling operators are not directly subject to AUSTRAC oversight, Australian payment processors and banks that handle gambling transactions are. This means that even when a casino initiates a withdrawal quickly, the funds may be delayed at the banking layer due to AML screening, transaction monitoring, or the policies of individual financial institutions regarding gambling-related transfers. Players using bank transfers to Australian accounts sometimes experience delays of three to seven business days that originate entirely outside the casino’s control.
How Withdrawal Speed Is Actually Measured and Categorized
The term “fast payout” lacks a universally agreed definition in the Australian online gambling market, which creates significant scope for operators to make claims that are technically accurate but practically misleading. Some casinos advertise same-day withdrawals but apply that description only to the internal approval process — the time between a player submitting a withdrawal request and the casino’s finance team approving it for disbursement. The actual transfer to the player’s account may take an additional one to five business days depending on the payment method used.
A more rigorous framework distinguishes between three separate time components: the pending period, the processing period, and the settlement period. The pending period is the window during which a withdrawal request can be reversed by the player and during which the casino conducts identity verification and fraud checks. This period ranges from zero hours at some operators to 72 hours or more at others, and it is during this window that casinos sometimes engage in the practice known as “reverse withdrawal” or “cashback temptation,” where the casino interface makes it easy for players to cancel their withdrawal and return funds to their gaming balance. The processing period begins once the pending phase ends and the casino initiates the actual transfer. The settlement period is determined by the payment method and financial intermediaries involved and is largely outside the operator’s control.
Resources that systematically evaluate these distinctions provide substantially more useful information than those that simply report advertised timelines. FastpayoutCasinos has developed methodology specifically focused on the Australian market, testing actual withdrawal experiences across multiple payment methods and documenting the full cycle from request submission to funds availability. This kind of empirical testing, rather than reliance on operator-supplied information, is what distinguishes credible benchmarking from promotional content dressed up as reviews.
Payment method selection is the single largest determinant of withdrawal speed within a player’s control. E-wallets including PayPal, Skrill, and Neteller consistently deliver the fastest settlement times, typically ranging from instant to 24 hours once the casino’s internal processing is complete. This speed advantage exists because e-wallet transactions are processed through the provider’s own network rather than through the traditional banking system, bypassing many of the AML screening delays that affect bank transfers. Cryptocurrency withdrawals, particularly Bitcoin and Ethereum, can be even faster at the network level — transactions confirm within minutes to an hour depending on network congestion and the fee attached — though not all Australian-facing casinos support crypto withdrawals, and those that do sometimes impose their own internal processing delays that negate the blockchain speed advantage.
Credit and debit card withdrawals occupy a middle ground. Visa and Mastercard have both introduced faster payment rails in recent years, with Visa Direct enabling near-real-time card credits in markets where issuing banks support the feature. However, adoption among Australian banks has been uneven, and many players still experience three to five business day delays on card withdrawals. Bank transfers via the New Payments Platform, Australia’s real-time payments infrastructure launched in February 2018, offer the potential for near-instant settlement between participating institutions, but uptake among gambling payment processors has been limited, partly due to the AML compliance burden associated with gambling-coded transactions.
What FastpayoutCasinos Documents About Industry Standards and Operator Behavior
The methodology applied by dedicated withdrawal speed review resources reveals patterns that individual players would struggle to identify through personal experience alone. Because any single player interacts with a limited number of casinos and makes withdrawals infrequently, their data points are too sparse to distinguish between operator policy, payment method variability, and random processing delays. Aggregated testing across multiple accounts, payment methods, and time periods produces a much more reliable picture of how operators actually perform.
The data compiled on the FastpayoutCasinos site reflects testing conducted specifically with Australian payment methods and banking infrastructure, which matters because withdrawal performance can vary significantly by geography. A casino that processes withdrawals quickly for European players using SEPA transfers may perform quite differently for Australian players using domestic bank accounts or local e-wallet configurations. Geographic specificity in testing methodology is therefore not a minor detail — it is fundamental to the relevance of the findings for Australian players.
Several consistent patterns emerge from systematic review of Australian-facing casino withdrawal performance. First, the correlation between licensing jurisdiction and withdrawal speed is real but imperfect. MGA-licensed casinos do tend to perform better on average, partly because the regulatory framework imposes stricter financial management requirements, but there is substantial variation within that group. Some MGA licensees have internal approval processes that take 48 hours or more despite having the financial infrastructure to process faster. Second, casinos that have invested in automated KYC verification systems — using document scanning technology and database cross-referencing rather than manual review — consistently outperform those relying on human review teams, particularly during periods of high player activity such as weekends and public holidays.
Third, the relationship between casino size and withdrawal speed is counterintuitive. Larger operators with higher player volumes sometimes process withdrawals more slowly than mid-sized operators because their finance teams handle a greater absolute number of requests, creating queuing delays. Smaller operators with lower transaction volumes can sometimes process individual requests faster, though they may face greater liquidity constraints that cause delays when multiple large withdrawals are submitted simultaneously. The optimal withdrawal experience often comes from operators in the mid-range of market size that have invested in automated processing infrastructure without the volume pressure that slows down larger competitors.
Verification requirements represent another dimension of withdrawal speed that is often underappreciated by players until they encounter delays. Know Your Customer verification, required by virtually all licensed operators, involves confirming a player’s identity, address, and in some cases the source of funds. Operators that complete this verification proactively — prompting players to submit documents during or shortly after account registration — experience far fewer withdrawal delays attributable to KYC than those that defer verification until a player’s first withdrawal request. The industry term for this proactive approach is “upfront KYC” or “pre-verification,” and its adoption has increased since 2020 as regulators across multiple jurisdictions have pushed operators to conduct due diligence earlier in the customer relationship rather than at the point of a large withdrawal.
Practical Implications for Australian Players Evaluating Casino Withdrawal Policies
Understanding withdrawal speed standards at a conceptual level is useful, but Australian players benefit most from being able to evaluate specific operators before committing funds. Several concrete factors distinguish operators with genuinely fast withdrawal processes from those whose marketing claims outpace their operational reality.
The presence or absence of a pending period is one of the most telling indicators. Operators that impose a mandatory 24 or 48-hour pending period before processing begins are structurally incapable of delivering same-day withdrawals regardless of how their payment infrastructure performs. Some operators justify pending periods as a player protection measure — giving players time to reconsider withdrawals and potentially seek support if they are experiencing gambling-related harm — and this rationale has some legitimacy in the responsible gambling context. However, pending periods longer than 24 hours are difficult to justify on those grounds and are more plausibly explained by the operator’s desire to retain funds on the platform and the associated revenue opportunity if the player reverses the withdrawal.
Withdrawal limits also interact with speed in ways that are not immediately obvious. Many casinos impose weekly or monthly withdrawal caps, meaning that players who win large amounts cannot retrieve all their funds in a single transaction. A player who wins $10,000 at a casino with a $2,500 weekly withdrawal limit will take four weeks to fully withdraw their winnings, regardless of how fast each individual transaction processes. These limits are disclosed in terms and conditions but are rarely prominent in casino marketing materials, and they disproportionately affect players who have experienced significant wins — precisely the players for whom fast access to funds is most important.
The treatment of bonuses also affects withdrawal timelines in ways that are not always transparent. Wagering requirements attached to welcome bonuses and ongoing promotions must be satisfied before bonus-derived winnings can be withdrawn. Some operators apply these requirements in ways that delay withdrawals even when a player believes they have met the stated conditions, leading to disputes that can hold up funds for days or weeks while the operator’s compliance team reviews the player’s betting history. Operators with clear, consistently applied bonus terms and responsive dispute resolution processes are meaningfully different from those where bonus-related withdrawal holds are common.
Australian players should also be aware of the interaction between withdrawal speed and responsible gambling tools. Many operators allow players to set deposit limits, session time limits, and self-exclusion periods, and some also offer the ability to lock withdrawal limits in place so that they cannot be increased impulsively. The availability and usability of these tools is relevant to the withdrawal speed discussion because operators that prioritize player welfare tend to have more transparent and efficient withdrawal processes overall — the same organizational culture that invests in responsible gambling infrastructure tends to also invest in operational systems that process player requests efficiently and honestly.
The evolution of Australia’s online gambling market over the next several years will likely bring additional pressure on withdrawal speed standards. Growing player sophistication, driven partly by the availability of comparative information from review resources and partly by broader consumer expectations shaped by instant payment experiences in other financial services contexts, is pushing operators to compete more aggressively on withdrawal performance. At the same time, regulatory developments including potential reforms to the IGA and ongoing changes in offshore licensing jurisdictions will continue to reshape the compliance environment within which operators manage player funds. Players who understand the structural factors behind withdrawal speed — not just the advertised timelines — are better positioned to make informed choices in this evolving landscape and to recognize when an operator’s performance falls short of reasonable standards.
Ensuring Veracity of your Data
Earlier this year, Kate Crawford addressed this notion of data veracity in an excellent piece in Harvard Business Review titled The Hidden Bias of Big Data. Disputing the notion that if you have enough data, the numbers speak for themselves, she states correctly that humans give data their voice; people draw inferences from the data and give data their meaning. Unfortunately, people introduce bias, intentional and unintentional, that weaken the quality of the data.
Improving the veracity of your data requires minimizing the occurrence of different sources of errors. These sources are related to: sampling method, capitalizing on chance, missing data, research bias and poor measurement. Before making decisions using data, executives first need to answer the following questions.
1. What is (are) your hypothesis(es)?

Despite the popular notion that Big Data is about simply finding correlations among variables rather than identifying why these relationships exist, I believe that, to be of real, long-term value to business, Big Data needs to be about understanding the causal links among the variables. Hypothesis testing helps shed light on identifying the reasons why variables are related to each other and the underlying processes that drive the observed relationships. Hypothesis testing helps improve analytical models through trial and error to identify the causal variables and helps you generalize your findings across different situations.
With a plethora of variables and data sets at their disposal, businesses can test literally thousands of relationships quickly. The probability of finding statistically significant relationships among metrics greatly increases when the sheer number of relationships are examined. Often, due simply to chance, a statistically significant relationship between two variables is found when, in reality, there is no underlying reason why they should be related. Using these spurious findings to support your existing beliefs is a good recipe for making sub-optimal decisions.
What can you do? Have a hypothesis(es) and test it (them).
2. What are your biases?
 People tend to seek out / remember / interpret results that support their existing beliefs and ignore or discount results that do not support their beliefs. Referred to as confirmation bias, this cognitive short-cut can often result in wrong conclusions about your data.
People tend to seek out / remember / interpret results that support their existing beliefs and ignore or discount results that do not support their beliefs. Referred to as confirmation bias, this cognitive short-cut can often result in wrong conclusions about your data.
What can you do? Specifically look for data to refute your beliefs. If you believe product quality is more important than service quality in predicting customer loyalty, be sure to collect evidence about the relative impact of service quality (compared to product quality).
Also, don’t rely on your memory. When making decisions based on any kind of data, cite the specific reports/studies in which those data appear. Referencing your information source can help other people verify the information and help them understand your decision and how you arrived at it. If they arrive at a different conclusion than you, understand the source of the difference (data quality? different metrics? different analysis?).
Also, use inferential statistics to separate real, systematic, meaningful variance in the data from random noise. Place verbal descriptions of the interpretation next to the graph. A clear description ensures that the graph has little room for misinterpretation. Also, let multiple people interpret the information contained in customer reports. People from different perspectives (e.g., IT vs. Marketing) might provide highly different (and revealing) interpretations of the same data.
3. What is the sample size?
We rarely (never) have access to the entire population of things which interest us. Instead, we rely on measuring a sample of that population to make conclusions about the entire population. For example, we collect customer satisfaction ratings from a portion of our customers (sample) to understand the satisfaction of the entire customer base (population).
When you use samples to understand populations, you need to understand sampling error. Sampling error reflects the difference of the sample of data from the population of data from which that sample was drawn. Because the sample is only a subset of the population, our estimation includes error due to the mere fact that the sample is only a portion of the population.
What can you do? Use inferential statistics to help you understand if the observations you see in your sample likely reflect what you would see in the population.
4. What is the data source?
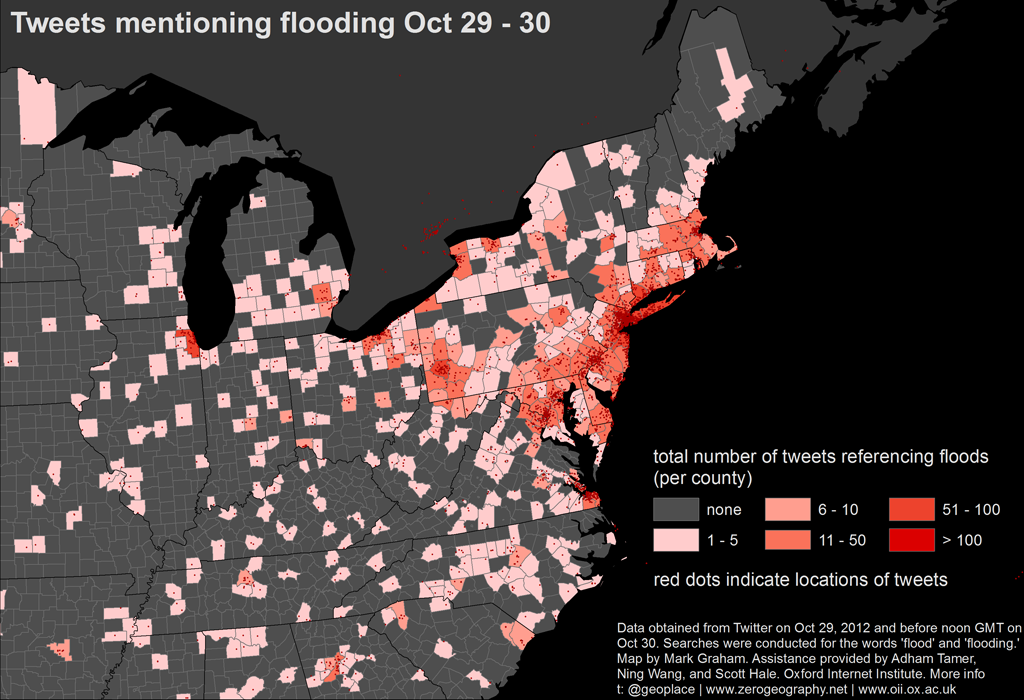 Even when we have large data sets, where sampling error seems to be minimized, we need to know the source of the data; data don’t occur in a vacuum. They can be intentionally generated/collected to solve a problem. For example, analyzing the location of thousands of tweets during Hurricane Sandy, the data show that more of the tweets about the storm originated from downtown Manhattan compared to New Jersey. Relying on simply counting the number of tweets, you might believe that the brunt of the storm hit downtown Manhattan. In reality, Sandy hit New Jersey, but, because of power outages in New Jersey that were due to the storm, people were simply unable to use Twitter from New Jersey.
Even when we have large data sets, where sampling error seems to be minimized, we need to know the source of the data; data don’t occur in a vacuum. They can be intentionally generated/collected to solve a problem. For example, analyzing the location of thousands of tweets during Hurricane Sandy, the data show that more of the tweets about the storm originated from downtown Manhattan compared to New Jersey. Relying on simply counting the number of tweets, you might believe that the brunt of the storm hit downtown Manhattan. In reality, Sandy hit New Jersey, but, because of power outages in New Jersey that were due to the storm, people were simply unable to use Twitter from New Jersey.
Additionally, it is estimated that only 18% of US adult web users use Twitter, the largest segment being between 18 and 29 years old. Also, in 2012, only 8% of shoppers use their mobile device in-store to tweet about their experience. Tweets, in the context of business, represent a small, perhaps biased set of data.
What can you do? Scrutinize the data source to help determine if the data are appropriate for the question you are trying to answer. Consider using different sources of data (e.g., metrics) to test your hypotheses. Multiple lines of converging evidence can be more convincing than a single line of evidence.
5. How good are your customer measures?
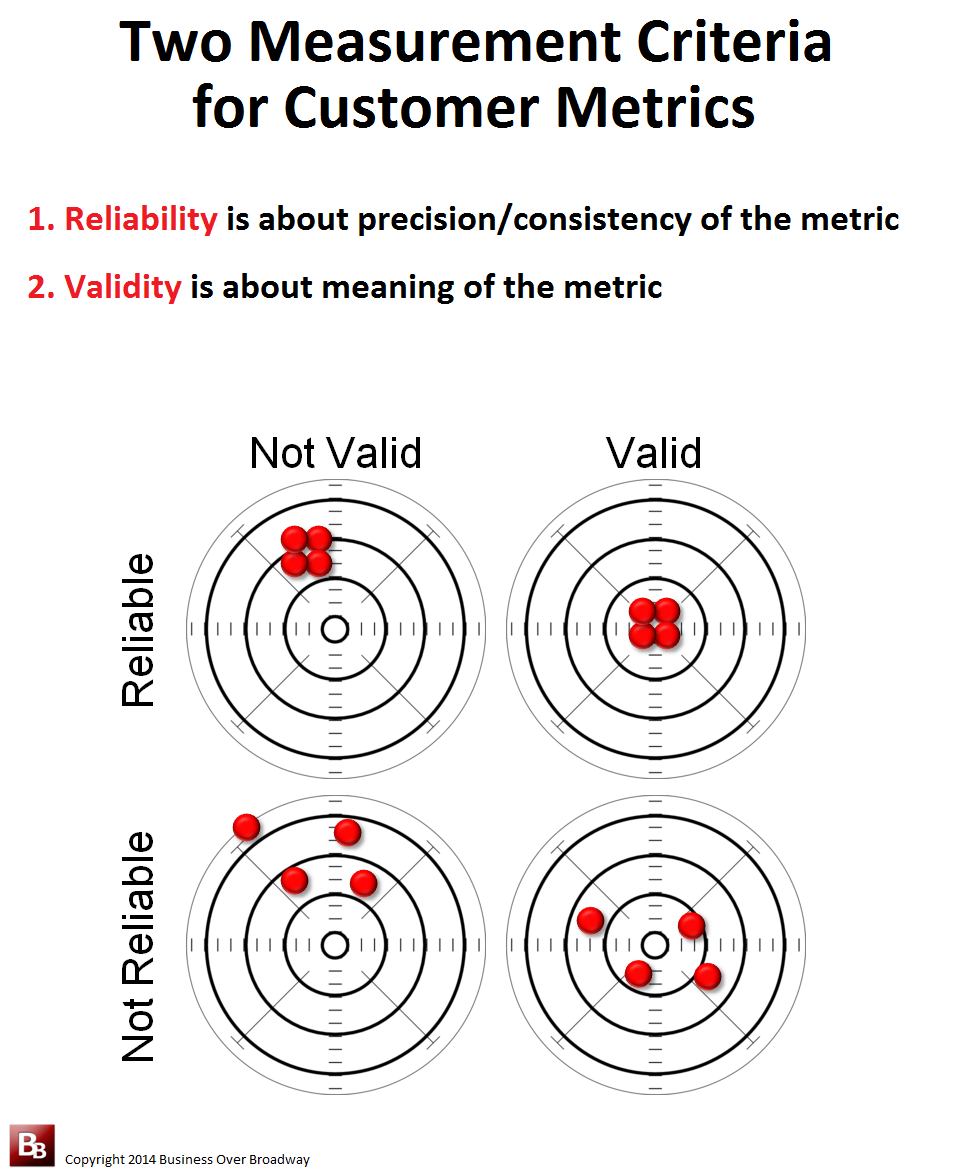 As businesses are trying to get value from extremely large, quickly expanding, diverse data sets, the notion of veracity is especially important when our data reflect “softer” entities like “satisfaction with the customer experience,” “customer loyalty” and “sentiment.” We spend time developing metrics and algorithms of the customer experience.
As businesses are trying to get value from extremely large, quickly expanding, diverse data sets, the notion of veracity is especially important when our data reflect “softer” entities like “satisfaction with the customer experience,” “customer loyalty” and “sentiment.” We spend time developing metrics and algorithms of the customer experience.
We measure these constructs with survey questions, sometimes from proprietary instruments that were developed by consultants. I have written about the quality of surveys and how companies need to be concerned about the reliability and validity of these instruments.
What can you do? Ask for evidence that the instrument is measuring something useful. If needed, acquire expertise in survey development/evaluation. Don’t rely only on the consultants’ reassurance that the instrument measures what they say it is measuring.
Final Thought
The quality of business decisions rests on the quality of business data (and the predictive models using them). While you might derive the slickest analytic model, when that model is based on data that are unreliable and invalid, that model’s performance in the real world (e.g., how well it predicts reality) suffers. As my good friend and business partner from Canada, Stephen King, says about data-driven decisions, “Garbage in. Garbage ooot.”

 Beyond the Ultimate Question
Beyond the Ultimate Question Measuring Customer Satisfaction and Loyalty (3rd Ed.)
Measuring Customer Satisfaction and Loyalty (3rd Ed.)
While I was in college, I learned from my research courses that the results of your study can never be trusted unless it was validated and was proven to be reliable. When I started working, I always carried this thought. However, in measuring customer behavior and patterns, I find it hard to find a software that provides a perfect data. But I think as long as your crm software fits your business needs, you have the edge.